Implementation of human behavior recognition based on visual skeletal model estimation by deep learning
{kind=link}
{kind=link}
Recent Posts
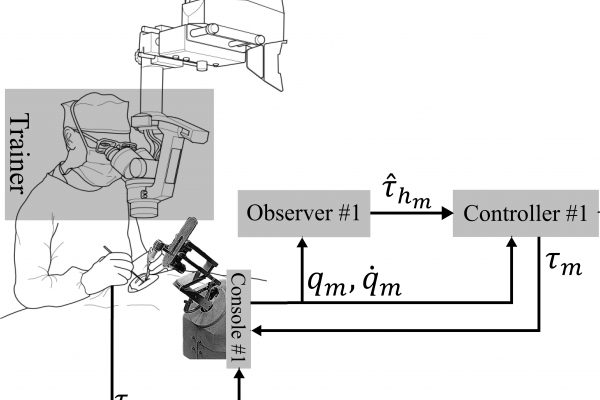
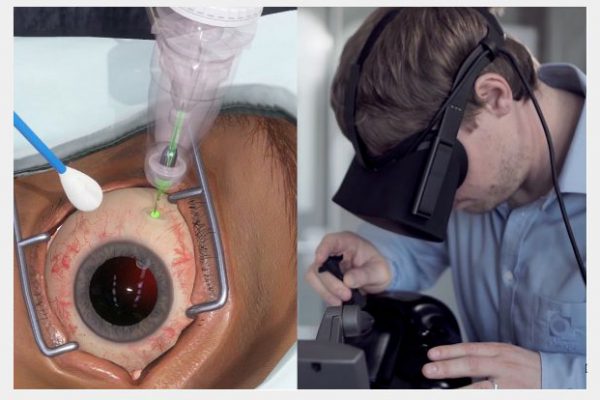
- Revolutionizing Ophthalmic Surgery: Navigating the Spectrum from Intraocular Robotics to Cutting-Edge Haptic Technology in Eye Surgery Training
- Resonant Peak Suppression Approaches for Improving the Dynamic Performance of DCX-LLC Resonant Converter Based Two-Stage DC–DC Converter
- Toward Keratoconus Diagnosis: Dataset Creation and AI Network Examination
- AI-Driven Keratoconus Detection: Integrating Medical Insights for Enhanced Diagnosis
- Development of Keratoconus Dataset and its diagnosis using artificial intelligence methods
Archives
- February 2024
- December 2023
- October 2023
- September 2023
- November 2022
- September 2022
- March 2022
- December 2021
- October 2021
- June 2021
- May 2021
- April 2021
- February 2021
- December 2020
- October 2020
- September 2020
- August 2020
- July 2020
- March 2020
- November 2019
- September 2019
- August 2019
- July 2019
- May 2019
- November 2017
- October 2017
- September 2017
Categories
- AI
- ARASH:ASIST
- Article
- Autonomous Robotics
- Autonomous Robotics
- AVMR
- Conference
- COVID-19
- Defence Session
- Dynamical Systems Analysis and Control
- Education
- Events
- Main
- MixedReality
- PACR Projects
- Parallel and Cable Robotics
- Presentation
- School
- Surgical robots
- Theses
- Thesis Defense
- Uncategorized
- Webinar
- Workshops
| S | S | M | T | W | T | F |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | |||
Tags
AI
ARASH:ASISI
ARAS Public Webinars
Article
Autonomous Cars
Autonomous Robotics
AVMR
Conference
COVID-19
Deep Leraning
depth map
Diamond Robot
Eagle eye robot
EKF
EYE
Farabi
ICROM
Khosravi
Nonlinear Control
Observer
PACR
Parallel Robot
Robotics
School
Self-Driving Cars
semantic segmentation
Speech
SR
Surgical robotic
Taghirad
Tehran
Theses
Thesis Defence
thesis defense
Webinar
webinars
Workshop
Workshops