Research interest of the Autonomous Robotics group lies primarily in the field of modern intelligent methods applied in a wide variety of fields from technologies relating driverless cars to autonomous land and aerial robots and surgical robotics. The current research theme in the group relates to the development of autonomous and commercial vehicles by implementation of state-of-the-art algorithms such as deep learning on visual data, in order to firstly develop driver assisting products as well as providing the technological grounds to move toward autonomous vehicles. Deep estimation from single images, dynamic object detection in 3D environments and obstacle avoidance for autonomous flight are some of the on-going projects of the AR group.
This research theme gets its root from the IROS 2005 Conference, where the overwhelming research work presented on SLAM in addition to the upcoming industrial needs motivates rigorous work in this area. The first Master student working on SLAM in the group was Ali Agha Mohammadi, who elaborates on different aspects of visual SLAM as well as implementation of Laser range finder based localization and mapping. Very soon other researchers explored a wide spectrum of research work on the consistency of EKF -based SLAM algorithms, as well as other state-of-the-art techniques developed in this area such as FastSLAM. Some work is done on developing more suitable and faster optimization techniques being developed for iSAM algorithms.The research results was shortly used in different robotic platforms developed in the group. Among many works done in this area, one may mention the projects implemented on our Silver robot for exploration in an unknown indoor environment, further promoted for obstacle avoidance of static and dynamic objects. The implementation of SLAM algorithms in outdoor applications using stereo vision cameras implemented on our other robotic platform Melon, was among the other challenges being fully worked out in the group. Soon we realized the importance and challenges existing in the 3D Mapping and localization, and a long term project was funded to develop a suitable 3D representation of the environment based on RGB-D sensory data. Using Kolmogorov complexity measures as well as Nurbs smoothing functions enables us to develop a very effective and computationally effective representation method for 3D visual data. Furthermore, trajectory planning and nonlinear control for navigation has been considered in the implementation of these techniques on autonomous ground robots as well as autonomous aerial drones.
Current Projects
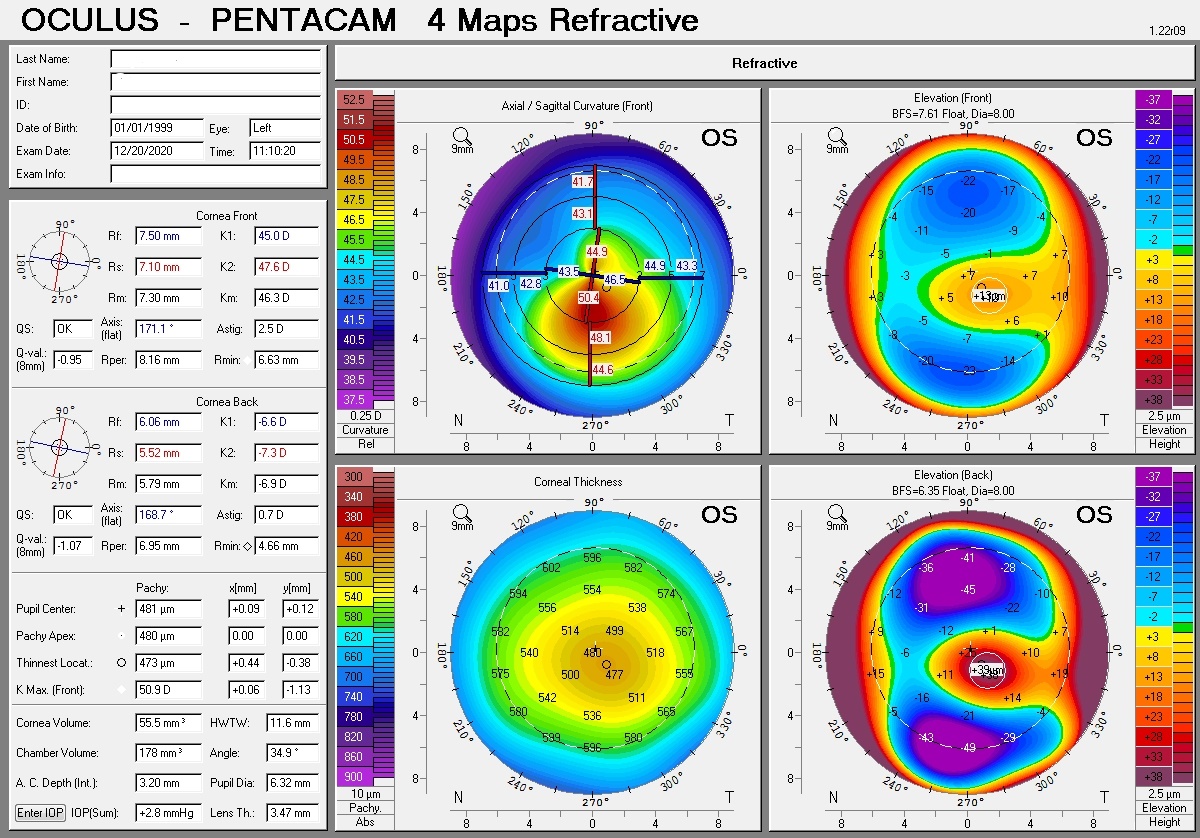
Ectasia is a condition in which the human cornea gradually becomes thinner and its slope becomes steeper, and eventually the pressure of the internal fluid of the eye causes the cornea to protrude forward. In general, everyone’s cornea is divided into three groups: Normal, Suspect and KC. Keratoconus is important because it limits performing refractive surgeries such as LASIK and femto. To limit KC usually preoperative care is performed using advanced imaging devices.
In this project, AI technology is used to diagnose KC categories based on four-maps eye images. in order to use this technology, it is necessary to produce a comprehensive database of medical images in the diagnosis of KC disease and its categories. This framework uses the output data of the Pentacam device, especially the Four Maps Refractive images. The data available at Farabi Hospital will be used to collect this data. In the first stage, the collected data need to be properly labeled and annotated to determine the patient’s health level in one of the three available classes.
The labeling process is very important for the data obtained from different sources because the reliability of the data is one of the important assumptions in creating the proper performance of methods based on artificial intelligence. For this means, the detailed expertise of physicians is needed to label and annotate these images. After the collection and labeling process, the potential challenges of this big data are identified and addressed, and the data and annotations associated with each data are aggregated and a comprehensive database is created to classify images.
An Online Implementation of Robust RGB-D SLAM
In this project an online robust RGB-D SLAM algorithm which uses an improved switchable constraints robust pose graph slam alongside with radial variance based hash function as the loop detector. The switchable constraints robust back-end is improved by initialization of its weights according to information matrix of the loops and is validated using real world datasets. The radial variance based hash function is combined with an online image to map comparison to improve accuracy of loop detection. The whole algorithm is implemented on K. N. Toosi University mobile robot with a Microsoft Kinect camera as the RGB-D sensor and the whole algorithm is validated using this robot, while the map of the environment is generated in an online fashion. The proposed algorithm is implemented on K. N. Toosi mobile robot in a step by step implementation hierarchy, by which the importance of adding each step to the algorithm is elaborated. Graphical and numerical results are reported for each step of the extended algorithm, by which it is verified that the proposed algorithm works suitably well with RGB-D data from Kinect camera. Furthermore, it is shown that the required execution time needed for each step is such that the algorithm is promising for implementation in real time with current graphical processing unit capabilities.
- Vision-Based Fuzzy Navigation of Mobile Robots in Grassland Environments
Suppose a wheeled mobile robot needs to autonomously navigate in an unstructured outdoor environment using a non-calibrated regular camera as its input sensor. For safe navigation of a mobile robot in an unknown outdoor environment, we need to do the following tasks:
• Ground plane detection
• Obstacle identification
• Traversable area specification
• Navigation
We consider that the robot is navigating in a rough terrain with static obstacles, perceives the required information from a single camera and makes navigation decisions in real-time. While the robot traverses in the real world, the relative positions of the obstacles vary in the image plane and consequently the 2D projections of these points, in our case extracted features, move in some direction depending on the heading of the robot and the location of obstacle in real world. It can be seen in Fig. 1, that camera movement toward an object, increases the scale of the object in the image plane and causes apparent motion of features in the image plane. When the robot moves toward an obstacle, projected features from the obstacle move upward in the image plane if they are located above the camera’s X-Z plane. On the contrary, if the features are located below the camera’s X-Z plane, they move downward as the robot draws near the obstacle. Taking into account this property and based on the movement of features in the image plane, the robot can decide whether the corresponding 3D point is an obstacle or not, and by this way it can avoid moving toward the obstacles in the environment. Using these two properties of the apparent motion of features and a fuzzy inference system, features can be compared in relation to each other and represented by linguistic fuzzy sets, which is the base of our vision-based fuzzy navigation algorithm
Vision-Based Fuzzy Navigation of Mobile Robots in Grassland Environments
Suppose a wheeled mobile robot needs to autonomously navigate in an unstructured outdoor environment using a non-calibrated regular camera as its input sensor. For safe navigation of a mobile robot in an unknown outdoor environment, we need to do the following tasks:
• Ground plane detection
• Obstacle identification
• Traversable area specification
• Navigation
We consider that the robot is navigating in a rough terrain with static obstacles, perceives the required information from a single camera and makes navigation decisions in real-time. While the robot traverses in the real world, the relative positions of the obstacles vary in the image plane and consequently the 2D projections of these points, in our case extracted features, move in some direction depending on the heading of the robot and the location of obstacle in real world. It can be seen in Fig. 1, that camera movement toward an object, increases the scale of the object in the image plane and causes apparent motion of features in the image plane. When the robot moves toward an obstacle, projected features from the obstacle move upward in the image plane if they are located above the camera’s X-Z plane. On the contrary, if the features are located below the camera’s X-Z plane, they move downward as the robot draws near the obstacle. Taking into account this property and based on the movement of features in the image plane, the robot can decide whether the corresponding 3D point is an obstacle or not, and by this way it can avoid moving toward the obstacles in the environment. Using these two properties of the apparent motion of features and a fuzzy inference system, features can be compared in relation to each other and represented by linguistic fuzzy sets, which is the base of our vision-based fuzzy navigation algorithm.
We address the 3D object tracking problem while using nonlinear estima- tors alongside deep learning techniques. By considering the autonomous vehicle as our case study, the problem is formulated as a structure from motion (SFM) where a nonlinear estimator performs the state estimation, and a deep learning technique produces the observations. In order to solve this problem, a switched state-dependent Riccati equation (SDRE) filter is proposed that robustly estimates both the lateral and longitudinal distances to frontal dynamic objects in the autonomous vehicle motion plane. The traditional SFM approach, however, cannot be encapsulated by an observable state-space model for the autonomous vehicle case; therefore, an extension is proposed to the SFM general form while implementing it in a multi-thread framework to address the multiple object requirement. By considering the estimations obtained from the filter on one hand, and the observations given by the deep learning part, on the other, the 3D tracking of frontal objects is realized in practice. The stability analysis of the switching SDRE filter in the modified SFM formulation is thoroughly performed in the discrete-time domain. To further investigate the effectiveness of the suggested methods, a Monte Carlo simulation is carried out, and analyzed, while the real-world implementation of the proposed method has been further accomplished by utilizing a Jetson TX2 board on an economical car (Quick) from SAIPA company. Since observations play a key role in estimating the required variables, image processing techniques are further studied in the second part of the thesis. In this regard, a hybrid paradigm consisting of an object detector alongside a classic OpenCV object tracker as well as a recurrent neural network is proposed to address some of the challenges such as occlusion and blurred images. Furthermore, a fully convolutional architecture is proposed to address the single object tracking task in a general-purpose tracking application. This model takes advantage of utilizing a novel architecture with various input branches to enforce multiple models in a single structure. The proposed approach is based on applying a convolutional neural network (CNN) and extracting a region of interest (RoI) in a form of a matrix at each frame. By this means, instead of analyzing the whole frame, just a small region is sufficient to track the intended object. Besides, a specific branch is taken into account to integrate the target template into the architecture making it possible to distinguish the intended object from similar objects in the surrounding area. Finally, to investigate the effectiveness and applicability of the proposed approaches, various simulations and comparison studies are conducted. Based on the reported results, it is shown that the capability of the proposed methods is equal to that of state-of-the-art (SOTA) methods in addressing real world applications.
Actine Member: Faraz Lotfi
Depth perception is fundamental for robots to understand the surrounding environment. As the view of cognitive neuroscience, visual depth perception methods are divided into three categories, namely binocular, active, and pictorial. The first two categories have been studied for decades in detail. However, research for the exploration of the third category is still in its infancy and has got momentum by the advent of deep learning methods in recent years. In cognitive neuroscience, it is known that pictorial depth perception mechanisms are dependent on the perception of seen objects. Inspired by this fact, in this thesis, we investigated the relation of perception of objects and depth estimation convolutional neural networks. For this purpose, we developed new network structures based on a simple depth estimation network that only used a single image at its input. Our proposed structures use both an image and a semantic label of the image as their input. We used semantic labels as the output of object perception. The obtained results of performance comparison between the developed network and original network showed that our novel structures can improve the performance of depth estimation by 52% of relative error of distance in the examined cases. Most of the experimental studies were carried out on synthetic datasets that were generated by game engines to isolate the performance comparison from the effect of inaccurate depth and semantic labels of non-synthetic datasets. It is shown that particular synthetic datasets may be used for training of depth networks in cases that an appropriate dataset is not available. Furthermore, we showed that in these cases, usage of semantic labels improves the robustness of the network against domain shift from synthetic training data to non-synthetic test data.
Active Member: Amin Kashi
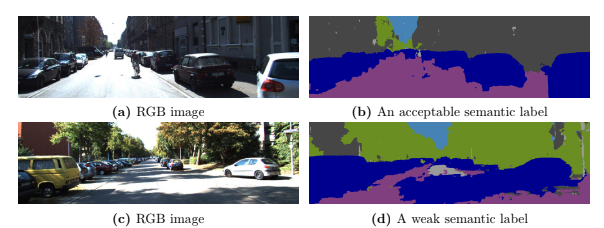
When conceptualizing the algorithm running on an intelligent robot through the glasses of a reductionist, a subsystem responsible for getting a sense of the location of the agent shows to be among the intuitively deduced modules. Whether we view location as a parameter that defines our position with respect to a fixed origin, or we define it through a relative perspective, a robot needs to have a notion of its placement in the world to be able to make appropriate decisions and perform the necessary actions while reacting to the dynamic world around it. However, this dynamic nature of the world presents problems such as flawed describers and unreliable observations that make it challenging to use straightforward solutions to perform localization through low-level information gathered by the sensors mounted on the robot. Therefore, approaches are needed that are able to exploit the semantic information embedded in observed scenes and extract higher-level information about the world around them that are robust to such issues. Moreover, by leveraging multiple sensors, information from modalities where the source of data varies to a suitable extent in between the said modalities may be gathered and fused to form a joint high-level representation of the state of the robot, further adding to the reliability of the localization system. In this thesis, our goal is to design and experiment with neural network architectures and create learning paradigms that incentivize the extraction of robust features through a representation learning procedure where the inputs to the network are not preprocessed. We propose mechanisms and objectives that allow the network to disregard faulty input information while achieving interpretability that allows the system to communicate its uncertainty about the estimates based on the provided inputs. Moreover, we take a hybrid approach to global localization of the robot where physical and learning based models are combined to form a multilevel localization approach in order to increase the flexibility of the pipeline. We perform comprehensive experiments to show our motivation while comparing our approaches to the state-of-the-art methods quantitatively and qualitatively. We analyze the proposed approaches through custom designed interpretation methods to get in-depth intuition on how our algorithms add to the literature and improve upon the state-of-the-art algorithms. Thereafter, we provide an overview of the branches of our work that can be explored further while delineating the potential future of the field.
Active Member: Hamed Damirchi

Past Projects

Depth perception is fundamental for robots to understand the surrounding environment. As the view of cognitive neuroscience, visual depth perception methods are divided into three categories, namely binocular, active, and pictorial. The first two categories have been studied for decades in detail. However, research for the exploration of the third category is still in its infancy and has got momentum by the advent of deep learning methods in recent years. In cognitive neuroscience, it is known that pictorial depth perception mechanisms are dependent on the perception of seen objects. Inspired by this fact, in this thesis, we investigated the relation of perception of objects and depth estimation convolutional neural networks. For this purpose, we developed new network structures based on a simple depth estimation network that only used a single image at its input. Our proposed structures use both an image and a semantic label of the image as their input. We used semantic labels as the output of object perception. The obtained results of performance comparison between the developed network and original network showed that our novel structures can improve the performance of depth estimation by 52% of relative error of distance in the examined cases. Most of the experimental studies were carried out on synthetic datasets that were generated by game engines to isolate the performance comparison from the effect of inaccurate depth and semantic labels of non-synthetic datasets. It is shown that particular synthetic datasets may be used for training of depth networks in cases that an appropriate dataset is not available. Furthermore, we showed that in these cases, usage of semantic labels improves the robustness of the network against domain shift from synthetic training data to non-synthetic test data.
Active Members: Amin Kashi, Faraz Lotfi
Human Behavior Classification (HBC) can be counted as a vital part of any security system. It is undeniable that in almost all of the sensitive places either in society or in industrial sections, continuous monitoring of the situation is mandatory to realize various critical tasks. For instance, considering the pandemic related to COVID-19, it is imperative to track and record an infected person trajectories. To further enhance the performance in terms of accuracy, different body parts shall be detected while tracking a person. This may help not only to identify contaminated surfaces but also to classify dangerous behaviors. On the other hand, the interaction between individuals is another important point to give attention to, because people often change their decisions, moving trajectories, etc with respect to each other.
Active Members: Amin Mardani, Sina Allahkaram, Ali Farajzadeh, Faraz Lotfi

Dynamic Object Detection in 3D Environment
Dynamic object detection is the most important part of an environmental perception unit in any autonomous vehicle which is tending to perform safely in urban environments. In urban scenarios there are almost always multiple objects surrounding the vehicle, thus the problem of dynamic object detection is actually a Multiple Object Detection (MOD) problem. The effectiveness and accuracy of methods in this field are highly dependent on how the uncertainties are handled in the procedure, and in the operational level what combination of sensors are used to precept the environment.
Most MOD methodologies in the literature are based on the tacking-by-detection4 procedure. Potential movable objects are detected using data provided by modal sensors and the position and velocity of dynamic objects are tracked afterward. Continuous awareness of the kinematic states of the surrounding traffic participants is vital for modeling the perceived environment and furthermore for control actions and safety perseverance. This knowledge has to be real-time adjustable to be employable within reasonable time frames. This research field is now being conducted in different major branches in the AR Group. Research is being conducted by defining the master and Ph.D. Theses, in a collaboration with freelancer alumni. For more information, please the ARAS Driver-less Car Project.
Active Members: Faraz Lotfi
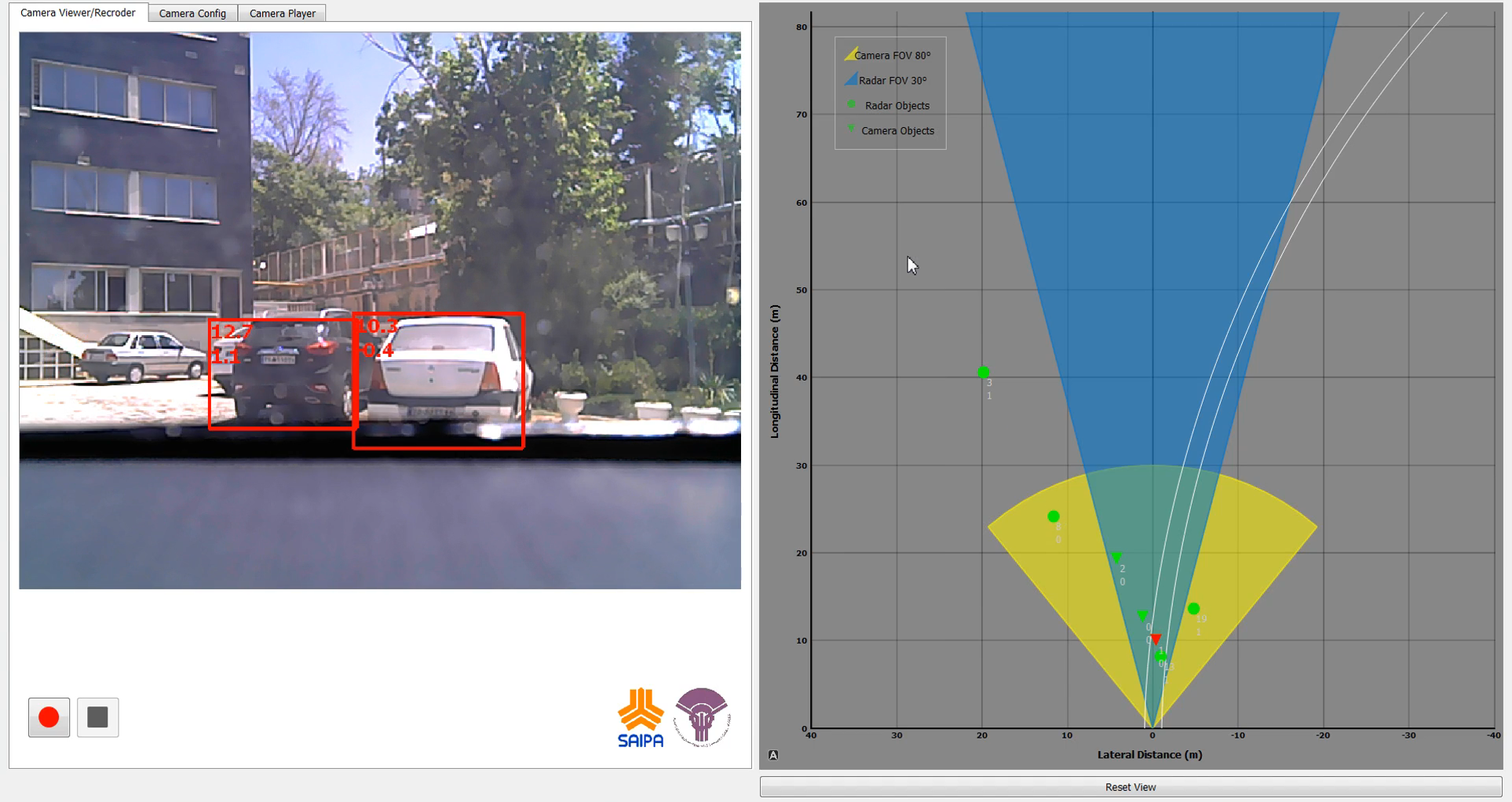
The Autonomous Car project has been started in a collaboration with SAIPA Group. The main goal of the project is to establish a software system for the autonomous driving process. The chosen platform for this project is an automatic vehicle called Quick from the SAIPA corporation. Road scene object detection (such as cars, bicycle, and pedestrian), real-time object detection and tracking, image based object distance estimation, and domestic data set gathering are some of the accomplished projects of this team. You may find more details about this project and it’s progress on ARAS autonomous car with Quick!
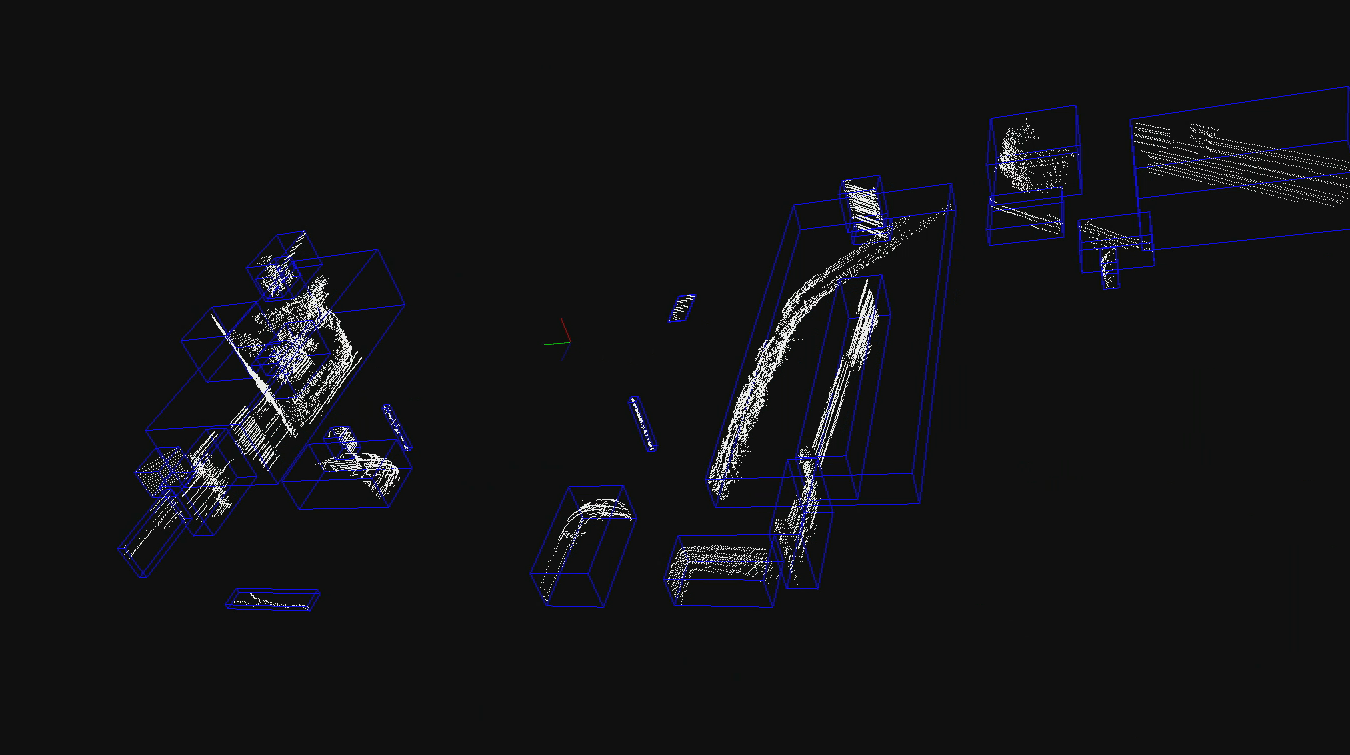
The Detection and Tracking of Multiple Moving Objects (DaTMO) Software Package project has been started to develop a software package for detection and tracking of dynamic objects in different road scenes. DaTMO-SP consists of two different software modules: Detection and Tracking. Until now the package is only designed and developed as a LiDAR based solution for DaTMO problem. Further modifications toward implementing sensor fusion methods on this package, is starting to take place in near future. For more details on this project please visit DaTMO-SP page.
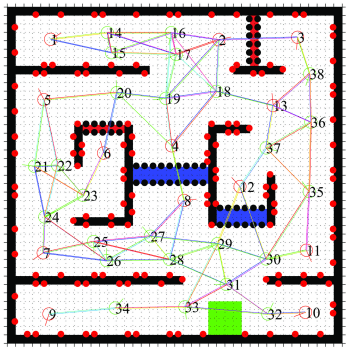
Mobile robot motion planning for search and exploration under uncertainty
Many problems of the sequential decision making under uncertainty can be modeled as the Markov Decision Process (MDP) and Partially Observable Markov Decision Process (POMDP) general frameworks. Motion planning under uncertainty is an instance of these problems. MDP and POMDP frameworks are computationally intractable and this problem restricts them to problems with small discrete state spaces and prevents using them in realistic applications. In this project, the motion planning is done for specific goals such as environment exploration, search and coverage. However, the presence of uncertainties makes them challenging tasks. In order to achieve a reliable plan and decision, these uncertainties should be considered in the robot’s planning and decision making. Therefore, the path planning for the exploration and search is modeled as an asymmetric Traveling Salesman Problem (aTSP) in the belief space in which the robot should search a series of goal points. Toward reducing the complexity of the aforementioned problem, the Feedback-based Information Roadmap (FIRM) is exploited. FIRM is a motion planning method for a robot operating under the motion and sensor uncertainty. FIRM provides a computationally tractable belief space planning and its capabilities make it suitable for real-time implementation and robust to the changing environment and large deviation. FIRM is proposed firstly by Dr. Ali Aghamohammadi as his Ph.D. thesis.
Using FIRM, the intractable traveling salesman optimization problem in the continuous belief space is changed to a simpler optimization problem on the TSP-FIRM graph. The optimal policy of the robot is obtained by finding the optimal path between each two goal points and solving the aTSP and then the policy is executed online. Also, Some algorithms are proposed to overcome the deviation from the path, kidnapping, finding new obstacles and becoming highly uncertain about the position which are possible situations in the online execution of the policy. Consequently, the robot should update its graph, map and policy online. The generic proposed algorithms are extended to the non-holonomic robots. In the online and offline phase, switching and LQG controllers as well as a Kalman filter for localization, are adopted. This algorithm can be implemented in practice and makes us one step closer to the solving Simultaneously Path planning, Localization and Mapping (SPLAM) problem.This algorithm is implemented in the Webots (video) and also on a real robot (Melon robot) (video). In both simulation and real implementation, we have used a vision-based localization based on the EKF.
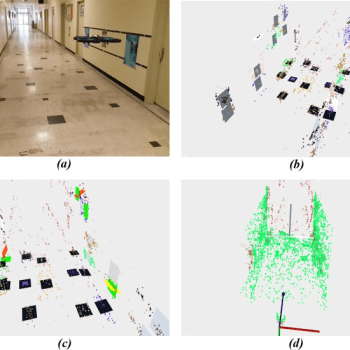
Autonomous Flight and Obstacle Avoidance of a Quad rotor By Monocular SLAM
In this project, a monocular vision based autonomous flight and obstacle avoidance system for a commercial quad rotor is presented. The video stream of the front camera and the navigation data measured by the drone is sent to the ground station laptop via wireless connection. Received data processed by the vision based ORB-SLAM to compute the 3D position of the robot and the environment 3D sparse map in the form of point cloud. An algorithm is proposed for enrichment of the reconstructed map, and furthermore, a Kalman Filter is used for sensor fusion. The scaling factor of the monocular slam is calculated by the linear fitting. Moreover, a PID controller is designed for 3D position control. Finally, by means of the potential field method and Rapidly exploring Random Tree (RRT) path planning algorithm, a collision-free road map is generated. The proposed system enables the robot to flies autonomously in unknown environment and avoids colliding obstacles. The proposed algorithm generally consists of two parts. Firstly, we obtain the 3D position of robot. For this, the 3D position of robot is estimated using Kalman Filter which fuses the monocular ORB-SLAM outputs and navigation data measured by on-board sensors of drone. Regarding the autonomous flight and obstacle avoidance, robot needs to have a perception of its environment. To fulfill this aim, we use the surrounding map of robot which is reconstructed by monocular ORB-SLAM. But, this map is sparse and not appropriate for autonomous applications. Therefore, we represented an algorithm that lines up and enriches the reconstructed map. In the next step we determine the motion next set point and generate a collision-free path between specified set point and current robot position.
For this, a dynamic trajectory generation algorithm is proposed to fly and avoid the probable obstacles autonomously in an unknown but structured environment by utilizing some path planning methods such as potential field and RRT. The algorithm has been evaluated in real experiments and the flight variables are compared with some external precise sensors. In the experiments, it is illustrated that robot can perform reliable and robust autonomous flight in different scenarios while avoiding obstacles. Moreover, the proposed system can be easily applied to other platforms, which is being extended and implemented in our future plans.

Loop Closure Detection By Algorithmic Information Theory: Implemented On Range And Camera Image Data
It is assumed that a wheeled mobile robot is exploring an unknown unstructured environment, while perceiving camera or range images as its observations. These observations may be obtained with a proper sensor such as 3-D laser scanner, Lidar, Microsoft Kinect camera, stereo pairs, or monocular camera. For autonomy, it is required to avoid obstacles, perceive surrounding environment, recognize revisited places, perform path planning, mapping, and localization for a long term exploration in an unknown area or navigation toward a goal. The concentration of this paper is on loop closure detection based on the complexity of the sparse model (image model, hereafter) extracted from either camera or range images. The mobile robot position estimation becomes unreliable by closing large-scale loops due to the accumulation of estimation error. Therefore, loop closure detection approaches based on the observation similarity, which are independent from the estimated position are more accurate. A sparse model is constructed from a parametric dictionary for every range or camera image as mobile robot observations. In contrast to high-dimensional feature- based representations, in this model, the dimension of the sensor measurements’ representations is reduced. Considering the loop closure detection as a clustering problem in high- dimensional space, little attention has been paid to the curse of dimensionality in the existing state-of-the-art algorithms.
Exploiting the algorithmic information theory, the representation is developed such that it has the geometrically transformation invariant property in the sense of Kolmogorov complexity. A universal normalized metric is used for comparison of complexity based representations of image models. Finally, a distinctive property of normalized compression distance is exploited for detecting similar places and rejecting incorrect loop closure candidates. Experimental results show efficiency and accuracy of the proposed method in comparison to the state-of-the-art algorithms and some recently proposed methods.
Notable Alumni
Ali Agha
Technologist at NASA-JPL, Caltech

Kasra Khosoussi
Postdoctoral Associate - LIDS, MIT
Amirhossein Tamjidi
Texas A&M University
Ehsan Mihankhah
Nanyang Technological University
Alireza Norouzzadeh Ravari
Director of Research Office, Tavanir Co
Publications
| Title | Abstract | Year | Type | Research Group |